
The models Washington banned are back
Claude Sonnet 5 landed, OpenAI is blinking on its IPO, China trained a frontier model on home chips, and Anthropic got caught tracking Chinese users…

💬 Editor’s Note
Two weeks ago I ended the issue on a cliffhanger. Washington had switched off the two best models on the planet, and nobody knew when they’d come back.
They came back this week. The export controls on Fable 5 and Mythos 5 got lifted, both models are live again, and Anthropic shipped a new Sonnet on top for good measure.
But read the fine print and the mood shifts. Getting the models back cost Anthropic a standing arrangement where the government gets early access to frontier releases and sits in on the safety testing. The models are yours again. The terms are not.
The other half of the week was quieter and, I think, bigger. Everyone stopped asking who has the smartest model and started asking who can afford to run one.
📰 Top News
Fable 5 and Mythos 5 are back, with strings attached

This is the other shoe dropping on the story that ended the last issue. On June 30 the US government lifted the export controls it slapped on Claude Fable 5 and Mythos 5 back on June 12. Fable 5 went live again globally on July 1, and Mythos 5 is back for a set of approved US organizations.
For anyone on a Claude subscription, though, back is doing a lot of work. On Pro, Max, and Team plans Fable 5 is capped at 50% of your weekly usage limits, runs off its own separate usage bar, and only through July 7, a seven-day window. After that it falls out of the included plans and moves to usage credits at $10 per million input tokens and $50 per million output, double what Opus 4.8 costs. The most powerful model Anthropic just fought to bring back is the one subscribers can barely touch before the meter starts.
Getting here wasn’t free. The original ban traced to an Amazon report showing Fable 5 could be prompted into finding software vulnerabilities and, in one case, writing code to exploit one. Anthropic’s own testing found that GPT-5.5, Kimi K2.7, and half a dozen older Claude models could do the exact same thing, so the panic was arguably about the category, not the model.
The part worth watching is what Anthropic agreed to on the way back. It’s now giving the government early access to frontier models and their safeguards before release, sharing threat intel ahead of publication, and standing up a team for round-the-clock monitoring of jailbreak reports. It’s also drafting a shared jailbreak-severity framework with Amazon, Microsoft, and Google.
Last issue, a government freezing a model looked like a one-off panic. This week it hardened into a process, with the labs helping write the rules.
https://www.anthropic.com/news/redeploying-fable-5
Claude Sonnet 5 costs more than the sticker admits

Amid all the government drama, Anthropic also shipped Claude Sonnet 5, and the headline number looked friendly: $2 per million input tokens and $10 per million output through August 31, then $3 and $15 after that. That is the same sticker as Sonnet 4.6. Read past the banner and it gets expensive fast.
Two things quietly push the real bill up. Sonnet 5 ships with a new tokenizer that turns the same text into up to 35% more tokens, so a job that cost you a dollar on 4.6 can cost noticeably more here at the very same per-token rate. Anthropic set the intro price to make the switch “roughly cost-neutral,” which is a careful way of saying the underlying rate went up and the discount is hiding it. On top of that, the model is tuned to spend more tokens by default, reasoning harder and checking its own work, which is wonderful right up until the invoice lands.
The independent numbers are worse than the pitch. On the Artificial Analysis index this week, Sonnet 5 came out both more expensive per task and less intelligent than Opus 4.8, Anthropic’s own flagship, and some testers clocked it running pricier than Fable 5 for ordinary work. Opus 4.8 sits at $5 and $25 per million tokens, so a Sonnet that can cost more per finished job than the model above it is a strange place to land.
The one thing it won’t do is the bright spot. Anthropic says Sonnet 5 can’t build a working software exploit, scoring a flat zero on the Firefox exploit test that Opus and Mythos clear. After the month Anthropic just had, a model that looks cheap and can’t be turned into a cyberweapon is the story it wants told. The bill is the story it would rather you skip.
https://www.anthropic.com/news/claude-sonnet-5
OpenAI is blinking on its IPO

OpenAI is leaning toward pushing its IPO to 2027, according to the New York Times. Bankers reportedly warned that shaky tech stocks, plus the ugly aftermath of SpaceX’s record IPO, would sap retail appetite for the offering Sam Altman wants to price at a trillion dollars.
The market took it personally. SoftBank, one of OpenAI’s biggest backers, dropped as much as 12% on the report, giving back the gains that had pushed it past Toyota in May.
Two issues ago the story was Anthropic beating OpenAI to the public markets. Now the story might be that nobody wins that race this year. Filing confidentially is easy. Facing a live order book while you’re still burning through a $122 billion war chest is the hard part.
Cognition made the case against one model for everything
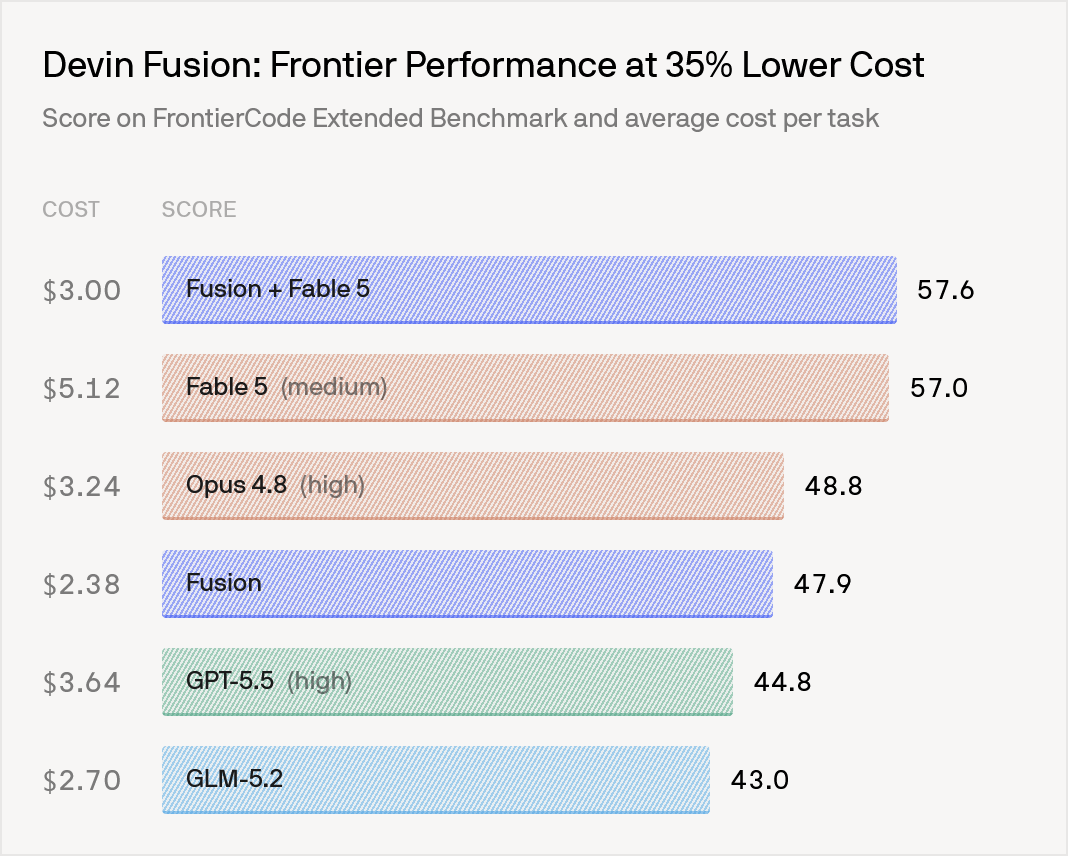
Cognition, the company behind Devin, shipped Devin Fusion, a harness that runs a frontier model and a cheaper sidekick model side by side and hands each task to whichever one fits. The pitch is blunt: engineering teams are lighting money on fire by using the most expensive model for every keystroke.
The numbers back it up. Fusion holds frontier-level performance on Cognition’s own coding benchmark while cutting cost by about 35%, and with Fable 5 in the mix it’s 41% cheaper. Internally, 88% of Cognition’s merged pull requests are now driven entirely by the automated router.
Their line sticks with me: you wouldn’t drive a Lamborghini to the grocery store, so why point a model that can find zero-days at rounding the corner of a button.
https://cognition.com/blog/devin-fusion
Arena turned the leaderboard into a $100M business

Arena, the crowdsourced model leaderboard that began as a Berkeley research project, just hit $100 million in annualized revenue eight months after switching on a paid product. Most people still think of it as a free open-source ranking.
The money isn’t in the leaderboard. It’s in selling labs the deep performance analytics behind it, gathered from more than 10 million human votes. That business grew from $30 million in January, and it now competes for the same dollars as human-labeling shops like Surge, Scale, and Mercor.
The tell for where AI value is pooling: the company that measures the models is worth $1.7 billion, and the thing it sells is other people’s opinions.
https://techcrunch.com/2026/06/29/arena-the-ai-leaderboard-everyone-uses-is-now-a-100m-business
🕵️ Undercovered
Anthropic wrote code to flag Chinese users, then quietly pulled it
Since April, Claude Code reportedly carried code that silently checked whether a user was affiliated with a Chinese AI lab. Nobody was told. After it surfaced this week and the spyware comparisons started, Anthropic rolled it back.
It fits an uncomfortable pattern. Anthropic already bars companies majority-owned out of China, and users there have spent a year routing around its geoblocks with proxies and borrowed identities. A hidden classifier that fingerprints users by affiliation is a different thing, and it landed the same week the company was busy positioning itself as the safety-first, government-trusted lab.
Barely anyone covered it under the noise of the model relaunches. They should have.
https://www.semafor.com/article/07/01/2026/anthropic-rolls-back-china-tracking-code
Meta decoded full sentences from brain waves, no surgery required
Meta released Brain2Qwerty v2, a system that reads what you’re typing straight from non-invasive brain scans, with no implant. It hit 61% word accuracy, and 78% for its best participant, up from the 8% that earlier non-invasive methods managed.
The catch keeps it lab-bound for now: it needs a room-sized magnetoencephalography machine and hours of recording per person. But accuracy scales cleanly with more data, and Meta released the full training code plus funded open datasets. For people who’ve lost the ability to speak, closing the gap to surgical implants without the surgery is a genuinely big deal.
https://ai.meta.com/blog/brain2qwerty-brain-ai-human-communication
DeepSeek made its model 85% faster to serve
DeepSeek shipped DSpark, a speculative-decoding upgrade to V4 that speeds up response generation by up to 85%. A small draft model guesses ahead, a bigger model verifies in batches, and the dead time between tokens collapses.
The quiet point is strategic. Faster serving means fewer GPUs per user, which matters more in China than anywhere else given the chip curbs. While US labs argue over who gets access to the best silicon, Chinese labs keep publishing tricks to need less of it.
Ford rehired the veterans it tried to replace with AI
Ford quietly brought back 350 veteran engineers, its gray beards, after automated quality systems failed to deliver. The COO admitted the company leaned harder and harder on AI quality checks and got disappointing results, so it rehired the specialists who hunt for failure points before a part ever reaches the floor.
The money line came from a VP: they assumed that feeding design requirements into AI would just produce a high-quality product, and it didn’t. Ford now credits the rehires with hundreds of millions in saved warranty and recall costs, plus the top spot among mainstream brands in a new quality survey. Same week, Zuckerberg told Meta staff that AI agents haven’t progressed as fast as he’d hoped. The hype is meeting the plant floor.
https://techcrunch.com/2026/06/28/ford-rehires-gray-beard-engineers-after-ai-falls-short
🗄️ The Vault
Strix

An open-source AI pentester that behaves like an actual attacker: it runs your code, finds vulnerabilities, and proves them with working exploits instead of the false positives static scanners spit out. It runs teams of agents in parallel, drops into GitHub Actions to block insecure pull requests, and has picked up 33k stars. Fitting tool for a week that was all about who can break what.
https://github.com/usestrix/strix
AirLLM

The counter-argument to renting a gated frontier model: run a big open one on hardware you already own. AirLLM keeps only one layer on the GPU at a time, so it’ll run a 70B model on a single 4GB card and DeepSeek-V3’s 671B on about 12GB, no quantization needed. One line of code, almost any open model.
https://github.com/lyogavin/airllm
turbovec

A Rust vector index that fits a 10 million document corpus into 4GB of RAM and searches it faster than FAISS. Everything stays local, nothing leaves your machine, and it drops into LangChain, LlamaIndex, and Haystack by swapping a single import. If you’re building RAG where privacy or memory actually matters, start here.
https://github.com/RyanCodrai/turbovec
Kestra

An open-source orchestration platform for data, AI, and infrastructure workflows, built around plain YAML you can write from the UI or from Git. Event-driven or scheduled, hundreds of plugins, runs scripts in any language, and designed to scale to millions of runs. The unglamorous plumbing that agent pipelines quietly need.
https://github.com/kestra-io/kestra
Printing Press
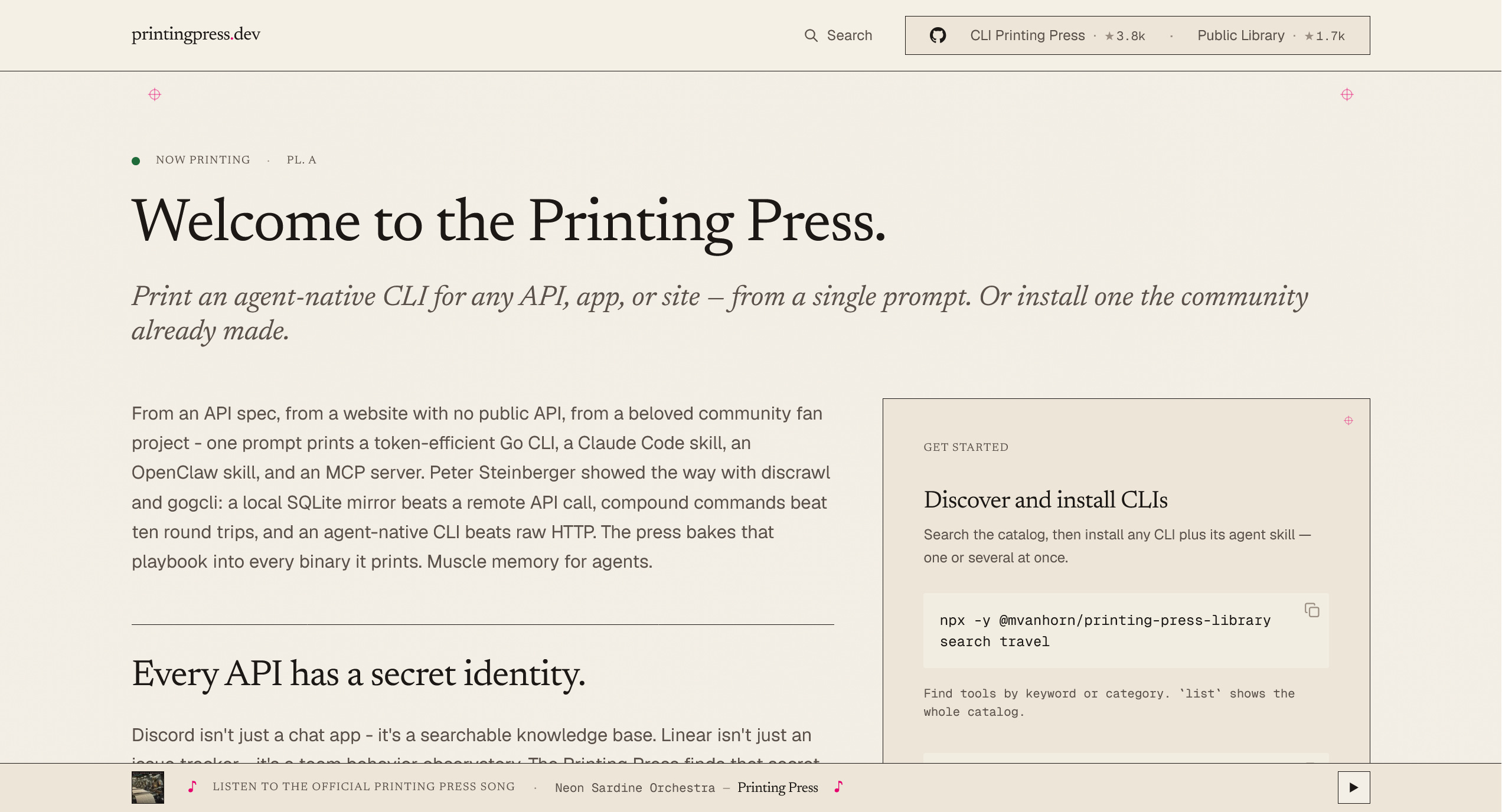
Point it at an API, a website with no public API, or a beloved fan project, and it prints an agent-native CLI from a single prompt, plus a Claude Code skill, an OpenClaw skill, and an MCP server. The idea, borrowed from Peter Steinberger: a local SQLite mirror and compound commands beat ten raw HTTP round trips. There’s already a community library of a few hundred to install.
🔥 This Week’s Pick
China trained a frontier model on home chips, and that’s the real story
While Washington spent the fortnight deciding which frontier models Americans are allowed to touch, China quietly answered a different question: whether it even needs American chips to build one.
Meituan, the food delivery giant, open-sourced LongCat-2.0 this week. It’s a 1.6 trillion parameter model with a million-token context window, which puts it in the same weight class as DeepSeek’s flagship V4-pro.
Here’s the part that matters. Meituan says it trained the whole thing end to end on a cluster of 50,000 domestic chips.
The word pre-training is the tell. DeepSeek’s V4-pro leaned on Chinese chips only for inference, the cheaper half where a finished model answers questions. Pre-training, where the model actually learns, is the brutally compute-heavy part everyone assumed still needed Nvidia. Meituan claims LongCat is the first trillion-parameter model to do both on home hardware.
Pair it with DeepSeek’s DSpark from the Undercovered section, which cuts serving cost by up to 85%, and a picture forms. The US export controls rest on a bet that cutting off the best silicon slows China down. The answer this quarter wasn’t complaints. It was a frontier-scale model trained without the banned chips, and a serving trick that needs fewer of them.
The same week a democratic government decided it needed a veto over its own labs’ releases, an authoritarian one showed it might not need the West’s hardware at all. Both of those are stories about control. Only one of them is going the way Washington planned.
🧪 This Week’s Experiments
Swap Opus for Claude Sonnet 5 on your next agentic task and see if you can tell the difference before you check the bill.
Point Strix at a repo you actually own before your next release and see what it turns up.
Rip out your managed vector database for turbovec on one RAG side project and check whether recall holds at a fraction of the memory.