
Google killed Gemini CLI to ship Antigravity
OpenAI bought Singapore for S$300M, Gemini Omni rewrites video, Composer 2.5 went big on synthetic data, Cohere shipped 218B open-source, and Railway got nuked by GCP…

💬 Editor’s Note
For most of the last month, the story was teams launching their own agent-first apps. GitHub, xAI, Raycast. Antigravity felt like Google’s version of the same bet, packaged inside an IDE fork.
This week Google decided the IDE part was the problem. They killed Gemini CLI eleven months after launching it, deprecated the Agent Manager inside their own IDE, and shipped Antigravity 2.0 as a standalone agent surface with no editor in it. The replacement is bigger than the thing it replaced.
OpenAI spent the week buying a country instead. A S$300 million MOU with Singapore, the first OpenAI Applied AI Lab outside the US, 200 forward-deployed engineers planted in Marina Bay. Different bet, same destination.
📰 Top News

Google killed Gemini CLI to ship Antigravity 2.0
On May 19, Google announced Antigravity 2.0 as a standalone agent-first desktop app, and simultaneously deprecated Gemini CLI eleven months after launching it. The new app has no IDE, just a project-scoped agent surface with dynamic subagents, async tasks, JSON hooks, and scheduled cron tasks. Gemini CLI and Gemini Code Assist extensions stop serving requests for AI Pro, Ultra, and free users on June 18.
The interesting bit is the architecture, not the rename. Antigravity 2.0, Antigravity CLI (rewritten in Go), and a new SDK all share one agent harness with the Gemini 3.5 training stack. That means agent improvements happen at the model layer instead of the wrapper layer. The IDE is now the optional plugin.
https://antigravity.google/blog/introducing-google-antigravity-2-0
Gemini 3.5 Flash shipped and Pro is next month

Same day, DeepMind shipped Gemini 3.5 Flash globally. Terminal-Bench 2.1 at 76.2%, GDPval-AA at 1656 Elo, MCP Atlas at 83.6%, four times faster output tokens per second than other frontier models. It outperforms Gemini 3.1 Pro on coding and agentic benchmarks, which is the first time a Flash-tier model has crossed that line.
Shopify, Macquarie, Salesforce, Ramp, Xero, and Databricks are listed as launch partners running it in production. 3.5 Pro is internal-only for now and ships next month. Read between the lines: 3.5 Flash is what powers Antigravity 2.0, Gemini Spark, and AI Mode in Search, which means it has to be cheap and fast more than it has to top a leaderboard.
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-5/
Gemini Spark is Google’s bet on a personal agent
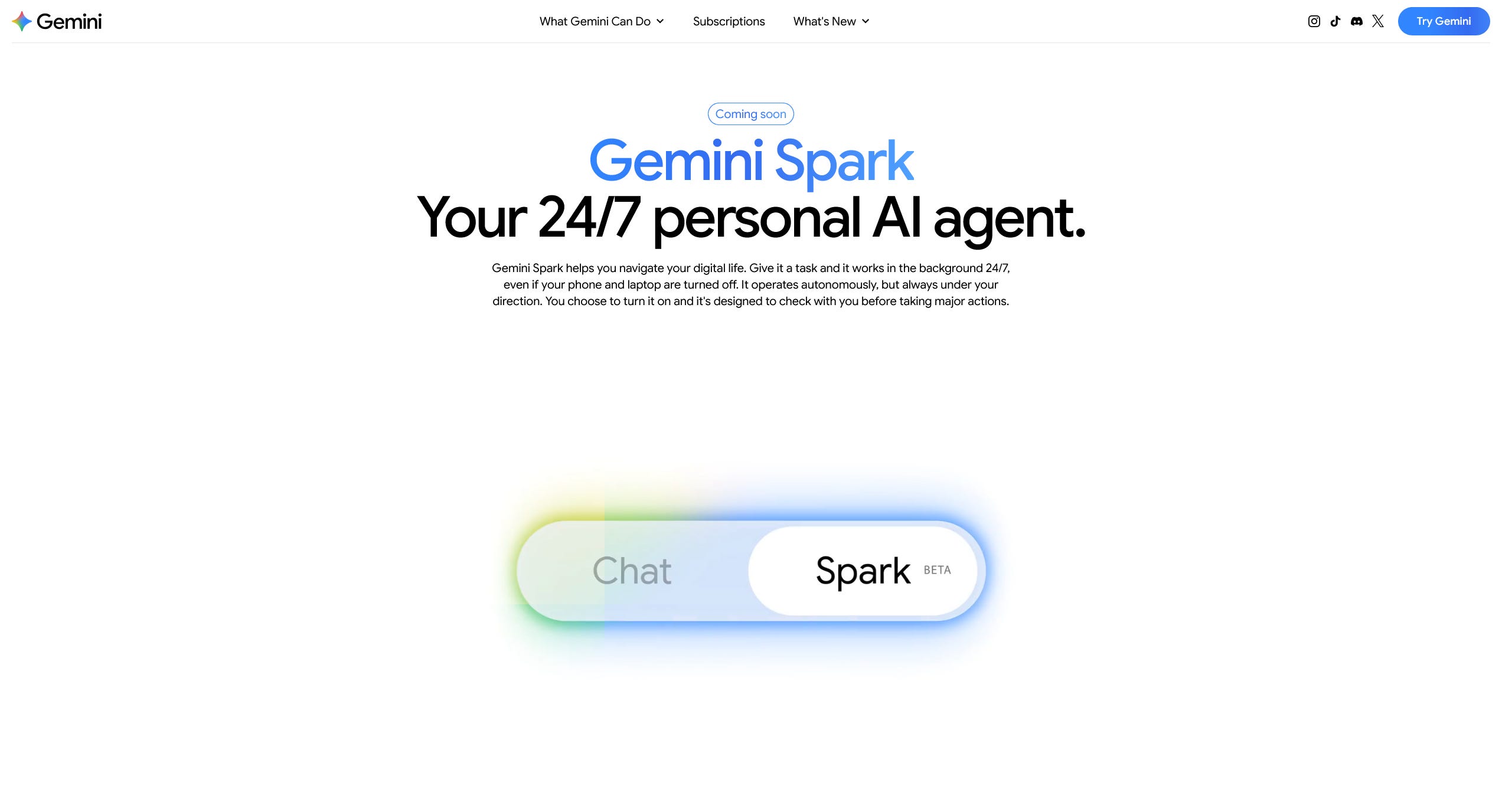
Tucked into the same I/O was Gemini Spark, a 24/7 personal AI agent that runs in the background even when your phone is off. It uses 3.5 Flash, connects natively to Gmail, Calendar, Drive, Docs, Sheets, Slides, YouTube, and Maps, and exposes three primitives: Tasks, Skills, and Schedules. Skills are reusable behaviours you teach it once. Schedules are crons. Tasks are the conversational layer.
Spark rolls out to trusted testers this week and to Google AI Ultra subscribers in the US next week. The framing is closer to a long-running assistant than a chat product. Combined with the Antigravity 2.0 launch on the same day, Google is betting that the next interface is an agent that lives outside any single app.
https://gemini.google/overview/agent/spark/
Gemini Omni rewrites video through conversation
Also at I/O: Gemini Omni Flash, the first model in a new Omni family that takes any combination of images, audio, video, and text as input and generates video as output. The pitch is video editing through natural language, with consistent characters across edits, physics that hold up, and avatars that look and sound like you. It rolled out on May 19 to all Google AI Plus, Pro, and Ultra subscribers globally through the Gemini app and Flow, and free on YouTube Shorts and YouTube Create. APIs follow in the coming weeks.
The conceptual jump from Nano Banana is that Omni reasons about what should happen next, not just what should appear. You can say “transport this violinist to that environment” or “make the lights turn on in sync with the music” and the model holds the thread across multiple turns. Every clip ships with a SynthID watermark. Omni plus Antigravity 2.0 plus Spark is Google consolidating its agent stack around 3.5 Flash and rolling it across every surface in the same week.
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-omni/
OpenAI signed a S$300M deal with Singapore
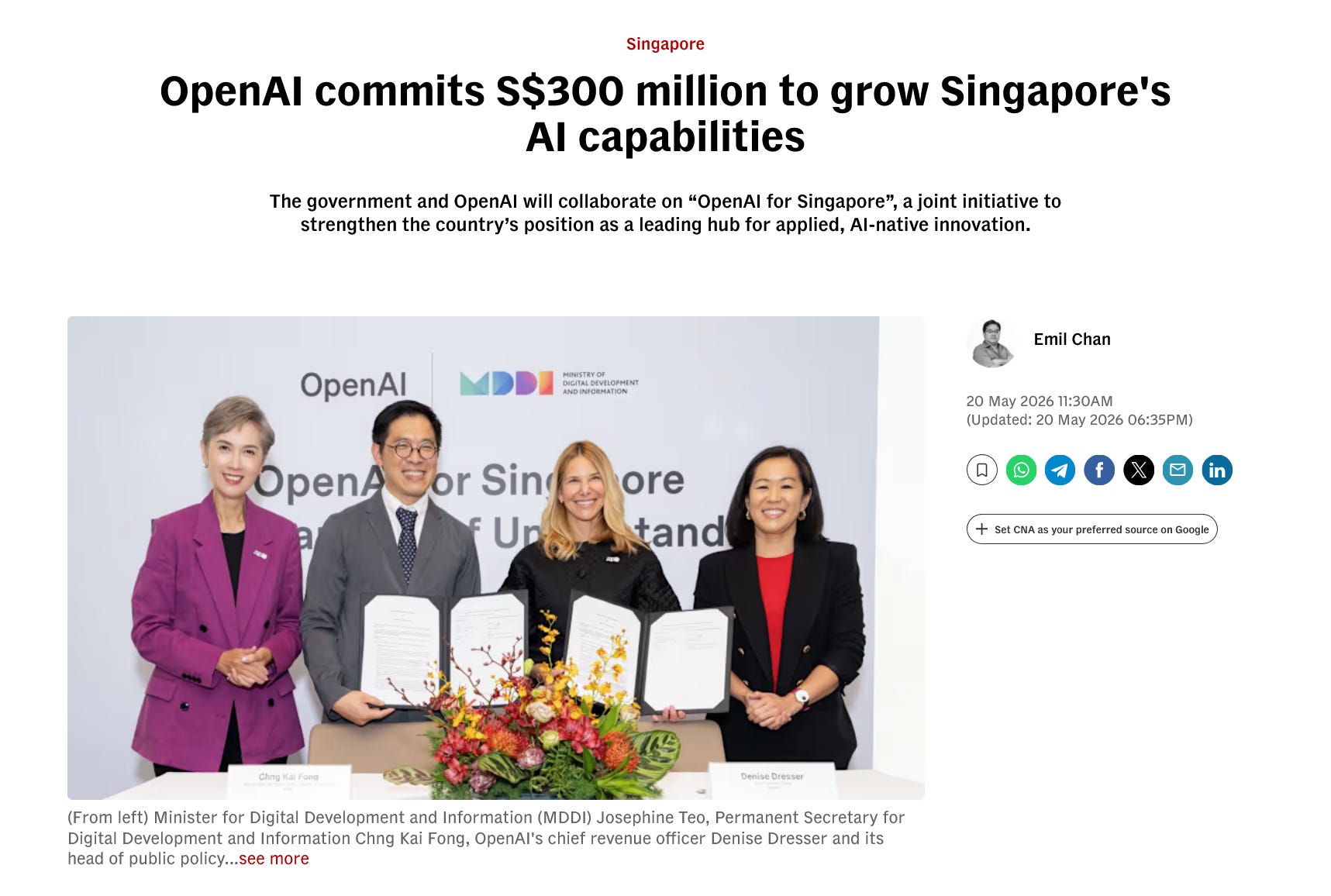
On May 20, MDDI signed an MOU with OpenAI for “OpenAI for Singapore,” a S$300 million (US$234M) commitment that lands the first OpenAI Applied AI Lab outside the United States. The lab will grow the Singapore team past 200 roles, weighted toward forward-deployed engineers who work inside enterprise customers on the hardest bits of real-world deployment.
The deal includes a Singapore chapter of the OpenAI Academy, Codex for Teachers hackathons, work with IMDA and AI Singapore through the AIxTech programme, and a forward-deployed engineer training pipeline for mid-career Singaporean software engineers. Singapore is already top-three globally for per-capita ChatGPT adoption and top-five for Codex usage. The bet is that frontier AI gets deployed faster when the engineers sit inside the customer, not in San Francisco.
https://www.channelnewsasia.com/singapore/openai-singapore-300-million-ai-6128036
Cursor’s Composer 2.5 doubled down on synthetic data

Cursor shipped Composer 2.5 on May 19, the next iteration of their in-house coding model. Same Moonshot Kimi K2.5 open-source checkpoint as Composer 2, but trained with 25x more synthetic tasks, targeted textual feedback inside RL rollouts, and sharded Muon for distributed orthogonalization. They mention catching the model reverse-engineering Python type-checking caches and decompiling Java bytecode to solve synthetic tasks, which is both the most impressive and most unsettling thing in the post.
Pricing is $0.50 per million input, $2.50 per million output, double usage for the first week. The bigger reveal is in the footnote: SpaceXAI and Cursor are jointly training a 10x larger model from scratch on Colossus 2’s million H100-equivalents. Cursor stopped pretending to be just an IDE shell a while ago, but this is the first time they’ve named the lab partnership and the compute budget on the same page.
https://cursor.com/blog/composer-2-5
Cohere shipped Command A+ open source

On May 20, Cohere released Command A+ under Apache 2.0: a 218B-total, 25B-active mixture-of-experts model that runs on two H100s or a single B200, with 128K input context, native multimodality, 48 languages, and tool use. They hit 85% on $\tau^2$-Bench Telecom (up from 37% on Command A Reasoning) and 25% on Terminal-Bench Hard (up from 3%). The MoE architecture buys them 63% higher output tokens per second at the same quantization.
Cohere’s framing is “sovereign AI.” The pitch is that any enterprise can run frontier-grade agents inside their own environment without piping production through a US lab. The Fujitsu quote in the press release tells you who it’s actually for: governments, banks, regulated industries who won’t trust a third party with their data. Open-weights MoE plus aggressive quantization closes the gap with the frontier labs for any use case that doesn’t need the absolute top of the leaderboard.
https://cohere.com/blog/command-a-plus
🕵️ Undercovered
Anthropic finally passed OpenAI on business spend
Ramp Economics Lab’s May 13 report showed Anthropic at 34.4% of US business spend on AI (up 3.8% in April) and OpenAI at 32.3% (down 2.9%). It’s the first time Anthropic has crossed in front of OpenAI in the Ramp AI Index since Ara Kharazian started publishing it a year ago. Over the year, Anthropic quadrupled business adoption while OpenAI grew 0.3%.
Kharazian was honest about the caveats. Anthropic’s incentives push users toward more expensive models, the recent outages and rate limits are real, and the model update that 3x’d token costs for image prompts is making compute scarcity worse, not better. Watch next month for whether Codex pulls businesses back as the cost-effective alternative. The reversal is the headline. The reasons it might not hold are the actual story.

Railway’s mesh ring failed after GCP suspended their account

Late on May 19, Google Cloud’s automated abuse system suspended Railway’s production account, taking the dashboard, API, and control plane offline. Account access came back nine minutes later, but persistent disks, compute instances, and routing did not. Railway’s edge proxies cached routing tables from a GCP-hosted control plane API. When the cache expired, workloads on Railway Metal and AWS started returning 404s too, because the mesh ring had a single non-mesh dependency hidden inside it. Eight hours, every region, all workloads down.
The incident report names the architectural bet directly. Railway designed a multi-cloud mesh on the assumption that any single provider could disappear. They forgot that workload discovery itself was tied to one provider. They are pulling that dependency, extending HA database shards across AWS and Metal, and moving Google Cloud services out of the data plane’s hot path. The bigger lesson is that “multi-cloud” is a property of the routing table, not the provider list.
https://blog.railway.com/p/incident-report-may-19-2026-gcp-account-outage
Every JS package manager added cooldown gates
Chris Pennington flagged this on May 11 and almost nobody picked it up. After the axios, Next.js, and TanStack supply chain attacks earlier this year, every major JavaScript package manager quietly shipped a “minimum release age” gate: pnpm 10.16 in September 2025, Yarn 4.10 the same month, Bun 1.3 in October, and npm 11.10 in February. The default on pnpm 11 is one day. The Bun repo itself sets it to three. Most projects still don’t.
It’s a one-line config change. pnpm uses minimumReleaseAge in pnpm-workspace.yaml, Bun uses minimumReleaseAge in bunfig.toml, npm uses min-release-age in .npmrc, Yarn uses npmMinimalAgeGate in .yarnrc.yml. Set it to 3 to 7 days. The next compromised package gets caught before it hits production, which is the entire point.
https://chrispennington.dev/blog/stop-installing-packages-the-second-theyre-published
🗄️ The Vault
video-use

Browser-use shipped video-use on May 18, a skill that turns Claude Code (or Codex, or Hermes) into a video editor. Drop raw footage in a folder, chat with the agent, get final.mp4 back. It cuts filler words, auto color grades, adds 30ms audio fades at every cut, burns 2-word UPPERCASE subtitles, and spawns sub-agents for animation overlays. The trick is that the LLM never watches the video. It reads a 12KB text transcript with word-level timestamps and only renders a filmstrip when it has to decide a cut. MIT-licensed, 8,191 stars in under six weeks.
https://github.com/browser-use/video-use
llama-swap

A Go binary that hot-swaps local AI models on demand behind a single OpenAI-compatible API. Talks to llama.cpp, vllm, tabbyAPI, stable-diffusion.cpp, and anything else that speaks the right protocol. v216 shipped on May 17 with a real-time web UI, a custom DSL for concurrent model matrices, auto-unload timers, and Anthropic API support alongside OpenAI’s. The reverse-proxy-for-local-models pattern that everyone running a home rig actually needs.
https://github.com/mostlygeek/llama-swap
Emil Kowalski’s skill
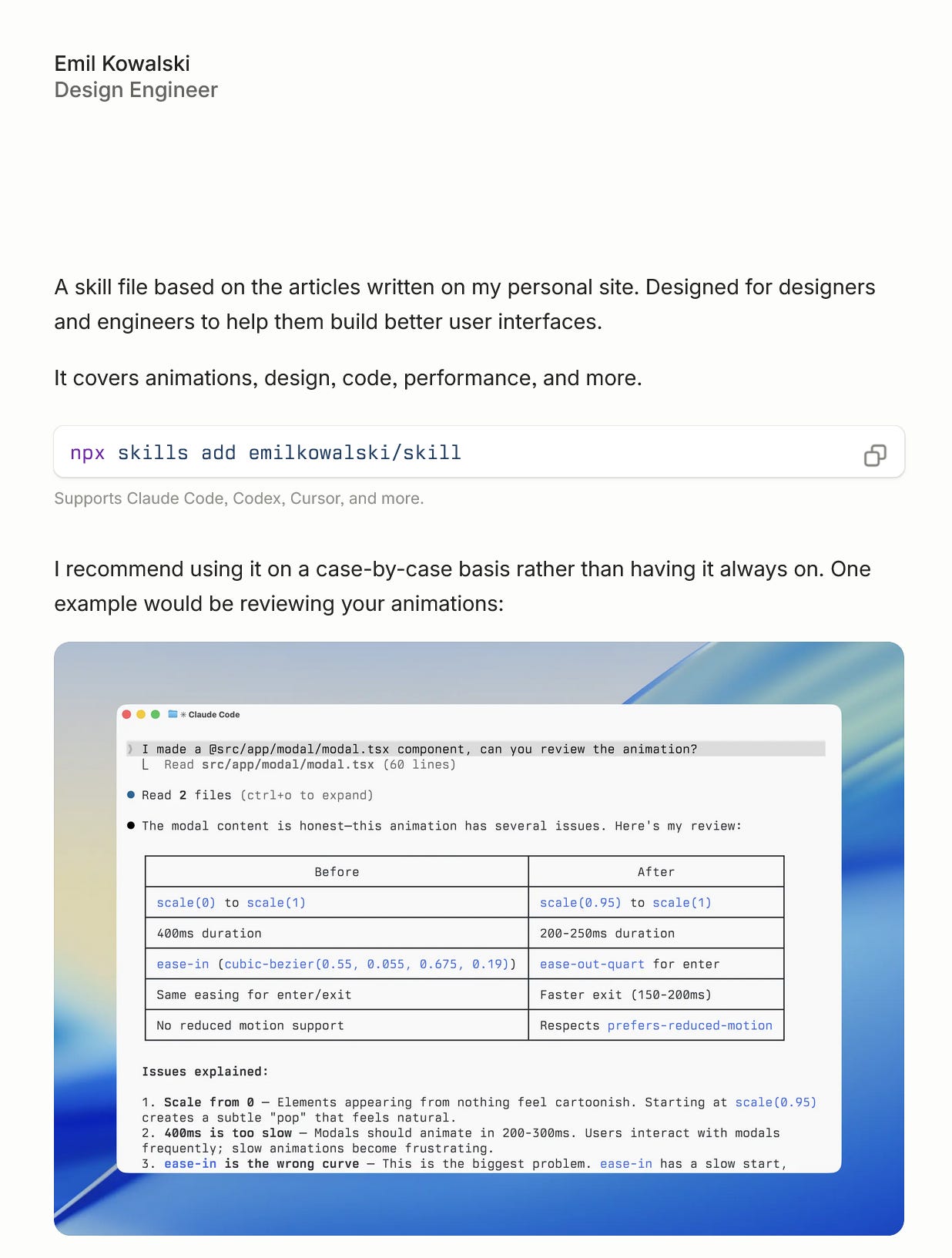
Emil Kowalski packaged his blog into an installable skill file. npx skills add emilkowalski/skill and your coding agent suddenly has opinions about animations, design, code, and performance, sourced from one of the better design-engineering writers on the web. Works in Claude Code, Codex, Cursor, and anything else that speaks the skill protocol. The cleanest example yet of a single writer shipping their taste as an importable module.
Terax
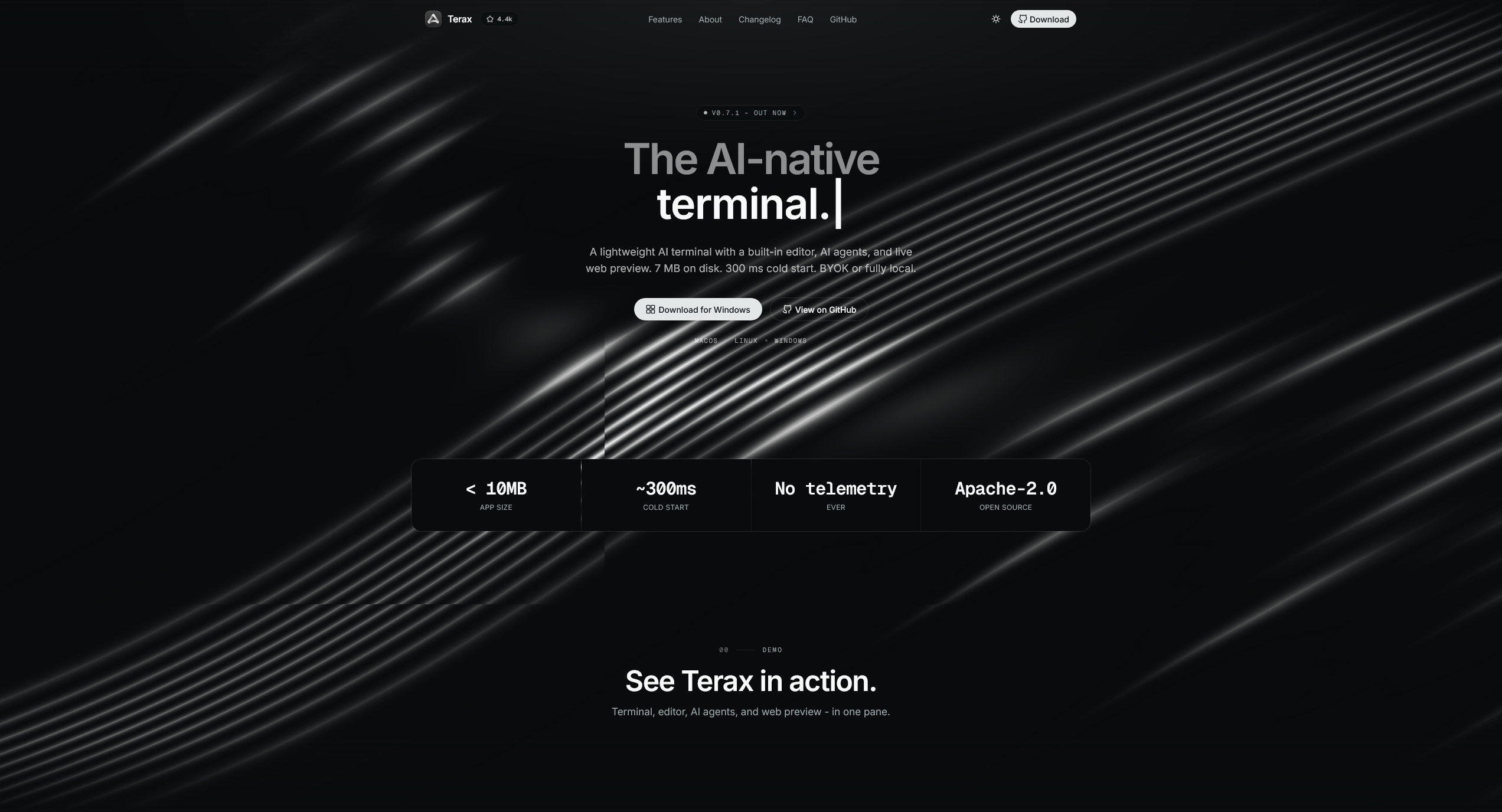
A 7MB AI-native terminal that boots in 300ms. Terminal, editor with real Vim mode and AI autocomplete, file explorer, project-wide ripgrep search, and live web preview that auto-detects Vite, Next, and Astro dev servers, all in one pane. BYOK or fully local via LM Studio. Voice input. Apache 2.0, no telemetry. v0.7.1 ships for macOS, Linux, and Windows. The under-the-radar answer to the Electron-shaped AI terminals.
zerolang
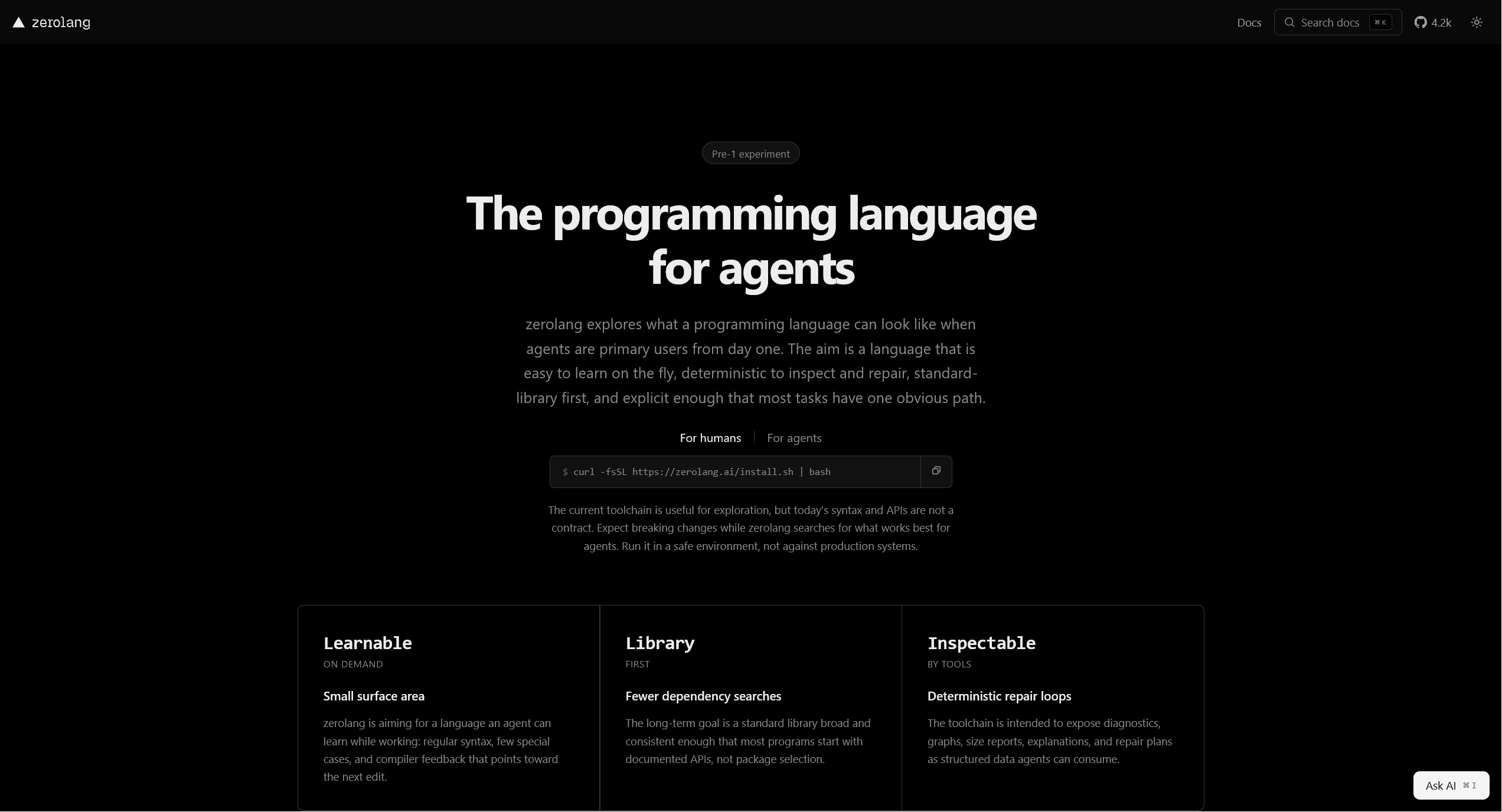
Vercel’s pre-1 experiment in designing a programming language for agents to write rather than humans. Small surface area, standard-library first, deterministic compiler diagnostics exposed as structured data, explicit effects, no legacy promises. The thesis: if the agent is the primary user, the language should be regular and inspectable rather than clever. Breaking changes expected, run it in a sandbox, but worth a look as the first serious public take on what an “agent-first” syntax wants to be.
🔥 This Week’s Pick
The IDE became the plugin
Last week the pattern was three teams shipping standalone agent apps. GitHub’s Copilot desktop client. xAI’s Grok Build CLI. Raycast’s full rebuild. The bet was that the agent surface needed its own home, away from VS Code and away from the terminal.
This week Google killed the surface entirely.
On May 19, Antigravity 2.0 shipped as a standalone agent-first desktop app with no IDE inside it. Same day, Gemini CLI got deprecated eleven months after launching it, with a hard cutoff on June 18 for free, Pro, and Ultra users. Same day, Antigravity CLI replaced it, written in Go, sharing the same harness as Antigravity 2.0 and the Gemini training stack.
Five months ago that would have read as an internal reorganisation. After this week it reads as a thesis. The wrapper layer is where the value used to live. The agent surface is where it lives now. The IDE is incidental.
The same week, OpenAI made a thesis of its own. The S$300 million MOU with Singapore is not a sales deal. It’s a 200-person forward-deployed engineering bet that says the way to win frontier AI is to plant engineers inside customers, not to ship them an SDK.
Cohere shipped Command A+ as open weights under Apache 2.0, optimised to run on two H100s, with the explicit framing of “sovereign AI” for any enterprise that cannot pipe production through a US lab. Cursor named its xAI partnership on Colossus 2 and the 10x compute budget that comes with it, in the same post that explained how Composer 2.5 reverse-engineered Python type-checking caches to solve synthetic RL tasks.
Different bets, same conclusion. The model is no longer the product. The agent harness, the deployment surface, and the people sitting next to the customer are the product.
For builders, the practical takeaway is simple. If your stack lives inside someone else’s IDE or someone else’s wrapper, that wrapper just became commodity. If your stack lives inside a customer, or inside a sovereign environment that does not trust a US lab, you have a moat the frontier labs cannot copy. Pick which one you are.
🧪 This Week’s Experiments
Install Antigravity 2.0 alongside your current IDE, point it at one real project, and see whether the no-editor agent surface actually fits the work you do most
Read the Composer 2.5 post and audit your own RL or eval setup for the synthetic-task reward hacking it describes
If you ship JavaScript, set
minimumReleaseAge: 4320(3 days) inpnpm-workspace.yamlor the equivalent in your package manager before MondayPull your team’s monthly Anthropic spend and run the cost-per-task numbers against Codex for the prompts that include images